OCR is the process of using technology to read characters from printed or handwritten text including from inside digital images of actual documents, such scanned paper documents.
Its primary function is to read a document’s text and convert the characters into code that may be used for data processing
OCR has emerged as a critical component of modern business operations. By 2023’s end, the worldwide OCR market is expected to be worth $70 million.
Applied OCR is also normally known as Intelligent Document Applications (IDA), below are the most known applications of OCR across Use Cases:
How does OCR work
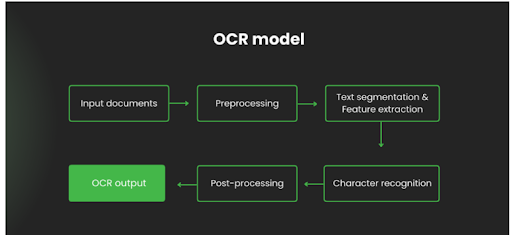
Preprocessing, Character Identification & Feature Extraction, Post Processing are the steps used in any OCR. A sample flow chart for a 6 step OCR classification process is shown
Image acquisition – Scanning a physical document and uploading its digital copyinto the OCR system.
Preprocessing – The process refers to the training data that are used in the OCR model. Preprocessing incorporates thresholding (transforming a physical document into a binary image), normalization, and noise reduction.
Segmentation – The segmentation technique aims to break a whole image into subparts, enabling the character recognition apps to process the document easily.
Feature Extraction – Used for extracting the most relevant information from the text image, enabling the software to recognize the characters in the text.
Classification – Allows to identify the character categories.
Post-processing – The process aimed at the reduction of noise and errors in the converted document.
Applications of OCR
Banking – Complete automation of Underwriting, Trade Finance & Risk Management, NDTL management etc.
Healthcare – NLP applied to OCR documents to automate medical transcription & reports
Legal – Digitization of legal forms, business contracts, emails & incorporation acts
Logistics – Automated processing of packages, tracking, registration & delivery.
Use Cases we help
We at Macgence AI can proudly claim our exposure in delivering high quality training data sets across all the above use cases, be it custom data sourcing or delivering OTS data for your plug & play we can partner with you to become an end-to-end AI training data provider.
Here are some of the samples of use cases we solved for our client –
A Client Case – A global SIFI wanting to optimize their underwriting process
Requirement – Source 10,000+ bank Statements across various languages for Doc OCR for its Loan Originating System
Execution – Batch wise sourcing of documents with constant client feedback on quality & PII redaction in line with model’s guidelines
Impact – Delivered 95%+ accuracy, PII redacted documents within a span of 8 weeks enabling the client to efficiently develop the model without fitting.
View our SAMPLE DATASET
The MACGENCE Way
TAT: Compliant high-quality data available at your disposal that comes with benefits of customization as well that can be quickly delivered
QUALITY: Our dataset goes through rigorous 2-level quality checks before delivery
COMPLIANCE: Adherence to both the mandatory compliances of HIPAA & GDPR
ACCURACY: Provides gives ~90% accuracy across different annotation types and model datasets
NO. OF USE CASES SOLVED: Experience across a diverse range of use cases